🦙使用 Llama.cpp 开始
概述
Open WebUI 让连接和管理本地 Llama.cpp 服务器变得简单灵活,可以运行高效的量化语言模型。无论您是自己编译了 Llama.cpp 还是使用预编译的二进制文件,本指南将指导您:
- 设置您的 Llama.cpp 服务器
- 本地加载大型模型
- 与 Open WebUI 集成以获得无缝界面
让我们开始吧!
步骤 1:安装 Llama.cpp
要使用 Llama.cpp 运行模型,您首先需要在本地安装 Llama.cpp 服务器。
您可以选择:
- 📦 下载预构建的二进制文件
- 🛠️ 或按照官方构建说明从源代码构建
安装后,确保 llama-server 在您的本地系统路径中可用,或记下其位置。
步骤 2:下载支持的模型
您可以使用 Llama.cpp 加载和运行各种 GGUF 格式的量化 LLM。一个令人印象深刻的例子是由 UnslothAI 优化的 DeepSeek-R1 1.58-bit 模型。要下载此版本:
- 访问 Unsloth DeepSeek-R1 在 Hugging Face 上的存储库
- 下载 1.58-bit 量化版本 - 约 131GB。
或者,使用 Python 以编程方式下载:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF",
local_dir = "DeepSeek-R1-GGUF",
allow_patterns = ["*UD-IQ1_S*"], # 仅下载 1.58-bit 变体
)
这将把模型文件下载到如下目录:
DeepSeek-R1-GGUF/
└── DeepSeek-R1-UD-IQ1_S/
├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
└── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
📍 记住第一个 GGUF 文件的完整路径 — 在步骤 3 中您将需要它。
步骤 3:使用 Llama.cpp 提供模型服务
使用 llama-server 二进制文件启动模型服务器。导航到您的 llama.cpp 文件夹(例如 build/bin)并运行:
./llama-server \
--model /your/full/path/to/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🛠️ 调整参数以适合您的机器:
- --model:您的 .gguf 模型文件路径
- --port:10000(或选择另一个开放端口)
- --ctx-size:标记上下文长度(如��果 RAM 允许可以增加)
- --n-gpu-layers:卸载到 GPU 的层数以获得更快性能
服务器运行后,它将在以下地址公开本地 OpenAI 兼容 API:
http://127.0.0.1:10000
步骤 4:将 Llama.cpp 连接到 Open WebUI
要直接从 Open WebUI 控制和查询您本地运行的模型:
- 在浏览器中打开 Open WebUI
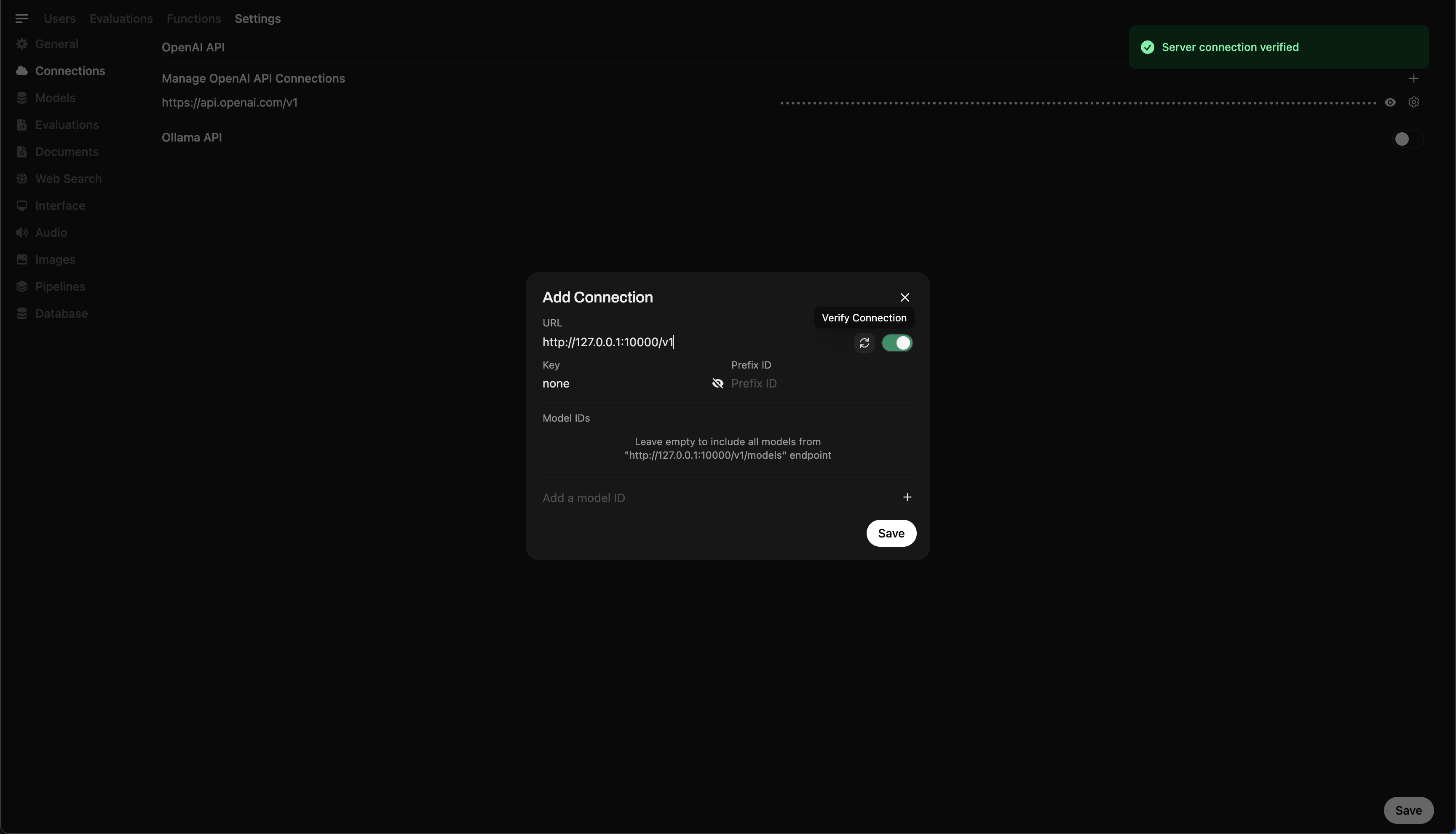
- 转到 ⚙️ 管理设置 → 连接 → OpenAI 连接
- 点击 ➕ 添加连接并输入:
- URL:
http://127.0.0.1:10000/v1
(如果在 Docker 内运行 WebUI,使用http://host.docker.internal:10000/v1) - API 密钥:
none(留空)
💡 保存后,Open WebUI 将开始使用您的本地 Llama.cpp 服务器作为后端!
快速提示:通过聊天界面试用模型
连接后,从 Open WebUI 聊天菜单中选择模型并开始交互!
您已准备就绪!
配置完成后,Open WebUI 让您轻松:
- 管理和切换由 Llama.cpp 提供服务的本地模型
- 使用 OpenAI 兼容 API,无需密钥
- 在您的机器上试验大型模型,如 DeepSeek-R1!
🚀 尽情试验和构建吧!